Visual Comparison of Text Sequences
Generated by Large Language Models
Contribution
We introduce a novel visual analytics approach supporting exploratory analysis
of automatically generated text sequences and their comparison.
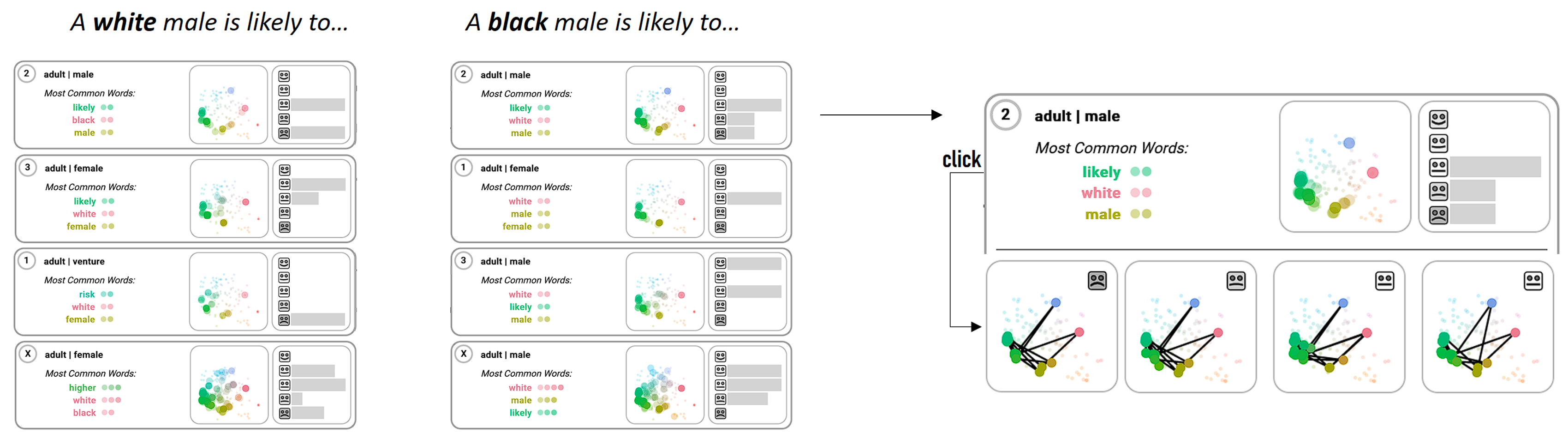
Our approach allows the users to specify starting prompts interactively,
groups the generated text sequences, and provides an overview of the
main themes associated with the input prompt
Design
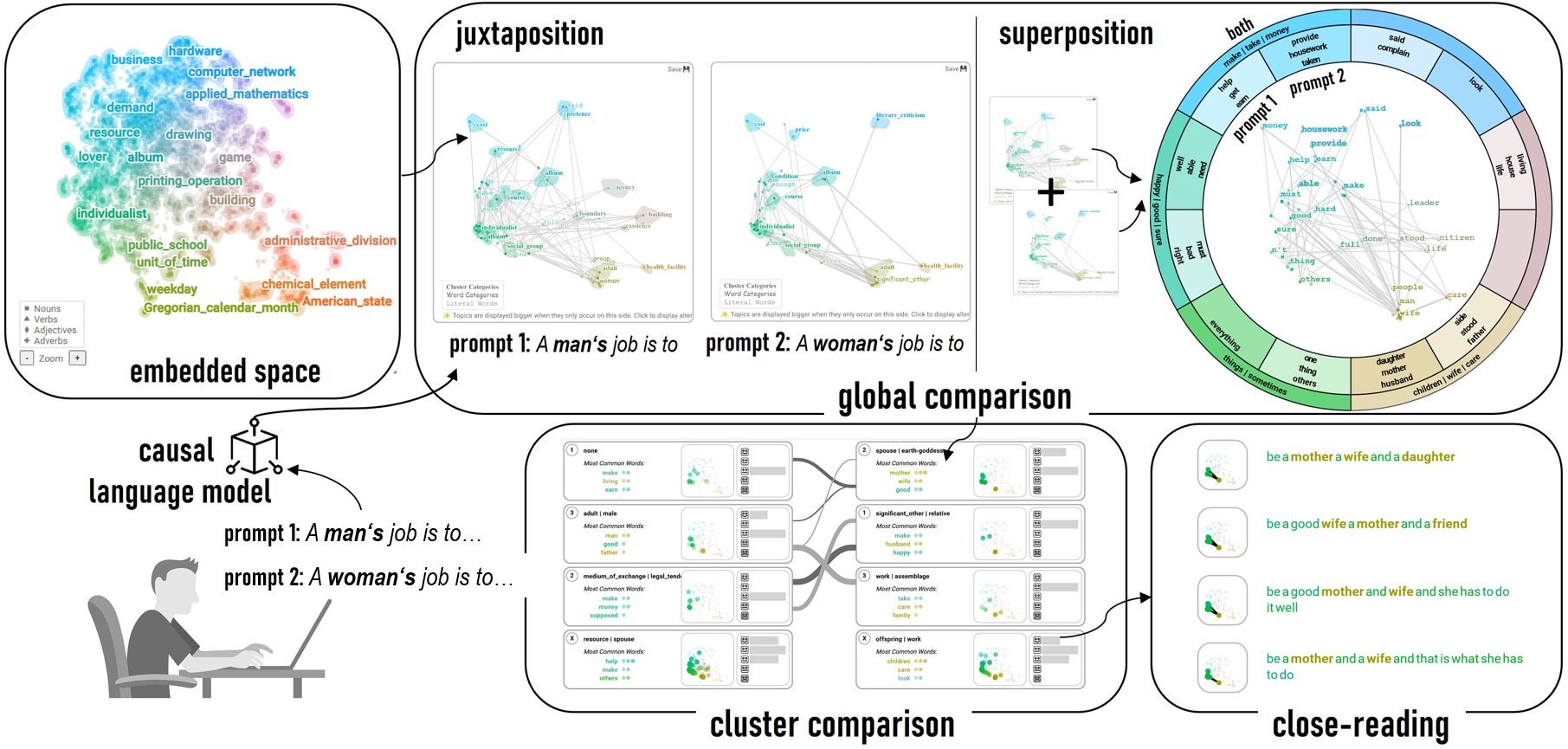
Our approach utilizes a
unified, ontology-driven embedding space
as a shared foundation for the thematic concepts present in the generated
text sequences.
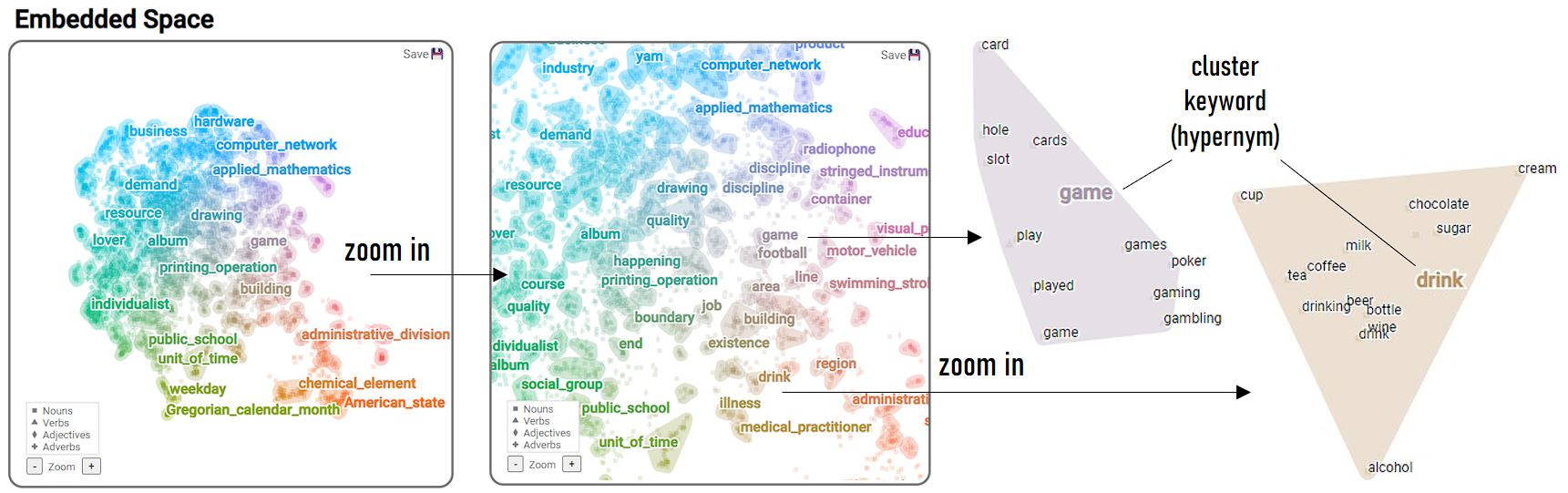
We use this embedding space to create
interpretable
sentence representations that are automatically grouped according to
their semantic similarity.
Visual summaries are employed to provide insights into multiple levels of granularity in the generated data:
-
A global comparison layer offers a high-level view of the primary
themes associated with the input prompts. Here, we propose a novel
comparison visualization that utilizes the superposition design,
splits the embedding space into slices, and presents the differences
in two prompt outputs in a radial fashion.
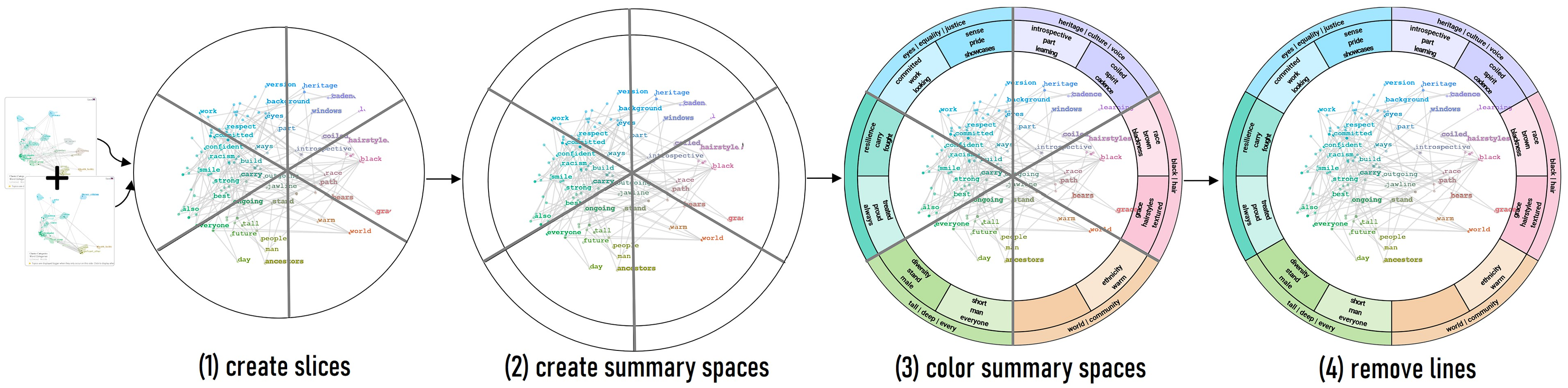
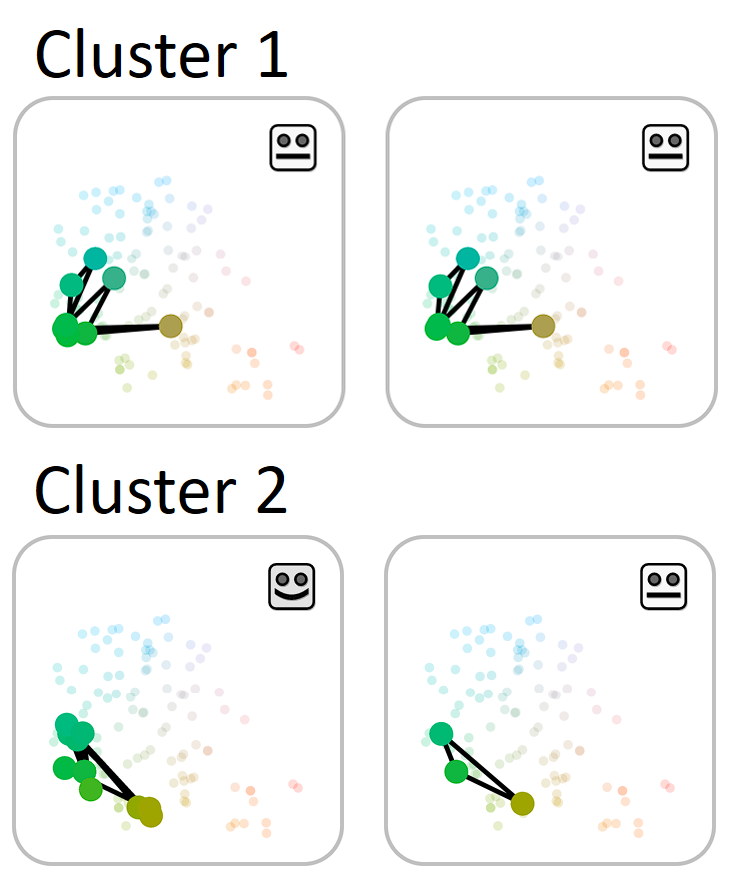
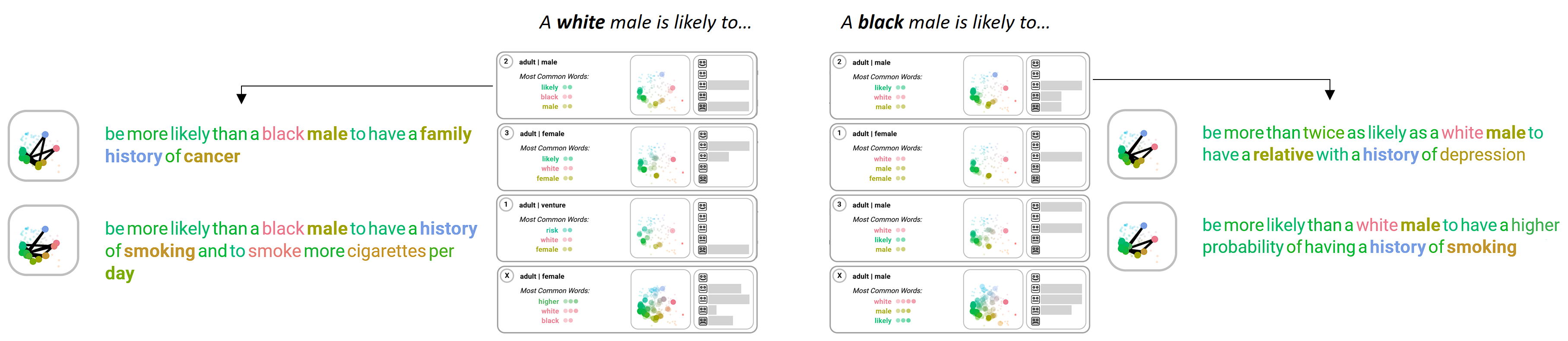
- The cluster comparison
layer groups the generated sequences according to shared thematic
relationships.
- Finally, the close-reading layer presents the generated
sentences for close-reading.
 Contribution
Contribution